FST JOURNAL
Artificial Intelligence
DOI: https://www.doi.org/10.53289/CTNT2190
The good and the bad actors of AI and how we manage them
John Gibson
.jpg?ext=.jpg&maxsidesize=150&resizemode=force)
John Gibson is the Chief Commercial Officer at Faculty, Europe's leading applied AI company. Prior to joining Faculty seven years ago, John spent over a decade working in government, most recently in the Prime Minister’s Policy Unit where he led work to support the growth of the UK tech sector. He also held roles as Director of Government Innovation at Nesta and as a Director at Fingleton Associates, where he designed the Open API Standard for Banking. He sits on the Board of Innovate UK.
Summary:
- We should think of AI as an incredibly important technology that we do (at this time) have total control over, not an outside threat like climate change or inflation.
- AI can deliver gigantic improvements in productivity. However, the same technology can also enhance the bad actor’s ability to do the thing they want it to do.
- In any scenario where the probability of Artificial General Intelligence (AGI) is greater than zero, that's something that needs to be taken very seriously and treated differently.
- We therefore need to distinguish between ‘narrow’ models, which regulators should seek to accelerate safely, and General ones, which require more caution.
- A question that deserves more attention is how do we build the technologies and the tools that allow us to interrogate, understand and control increasingly powerful models?
Adopting the right posture towards regulation
Without good regulation, less innovation and business activity happens. But it's really important that the debate around how we regulate AI adopts the right posture towards the subject.
We should not think of AI as an external threat that we have only limited control over; something we want to mitigate and manage like inflation or climate change. Instead we should take it as an incredibly important technology that we do (at least as we stand) have total control over. If we get things right, AI could help solve a lot of societal problems and create a lot of good changes for wellbeing and productivity at a scale and at a speed that we're not used to. We should start with that premise, and that regulators see their role in this as being one to accelerate the adoption of the technology and ensure a soft landing into society and that it delivers the goods that it can deliver, without creating the sort of harms that can happen if it's not well managed.
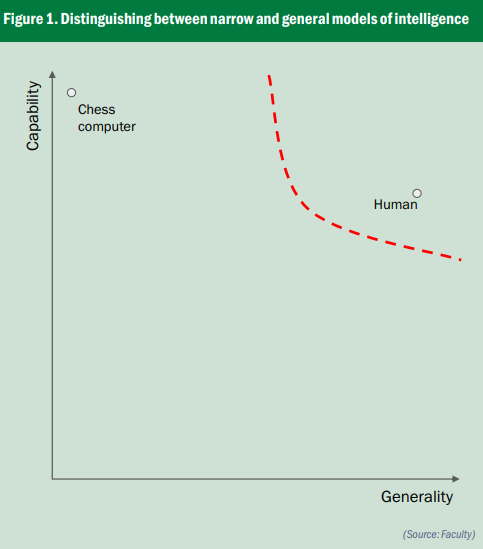
Distinguishing narrow and general models
There a bit of nuance to my point. I think the best way to unpack it is to visualise it.
Using the graph above, if you take the y axis as the capability of a system, and the x axis, you have how general it is. You can see a chess computer, it's extremely good at one thing, but it only does one thing. Then you take a human. Most humans are probably not as good as chess computers at chess, but they're very general machines that can do very many things at once. So I’ve drawn a rough red line on the top right region of that graph. The regulatory debate should be about defining the space and then figuring out what we can do to accelerate the stuff that happens on the left hand side of the red line, while also being pretty cautious about the things that might happen on the right hand side of the line.
Narrow models and good actors
Let’s take narrow models. Narrow models are those AI systems which do specific things. There’s broadly speaking two scenarios that have different consequences for how I think these models should be regulated. You've got narrow models used by good actors and narrow models used by bad actors. In the case of narrow models by good actors, what we're talking about here is organisations up and down the country using AI to make their business run better in some way. What we need to make sure here is that there aren't unintended consequences to the good faith actions that people are taking. In many ways, this is the simplest area to consider from a regulatory perspective which also has the objective to speed up implementation. This is where the vertical approach has been adopted in the UK focusing on the existing regulators. This is a series of potential harms that we know about already. There are just new ways of creating those harms that need to be carefully managed as you adopt the new technology.
The one caveat to my position on narrow models and good actors is in autonomous weapons. This deserves a category on its own. There was an awful lot of debate around this for a very long time and in Ukraine, it's happening in front of our eyes. We have Sakar drones that may or may not be acting autonomously in the field and delivering explosive payloads to people in the field without humans in the loop. It feels like that's a ‘Rubicon crossed’ and it doesn't feel like that's getting the sort of debate it needs. It's a scary technology, not least because of the risk of terrorists and others who want to do harm out of the battlefield, and in cities and so on.
Narrow models and bad actors
This leads to my second point on narrower models and bad actors. There’s more novel issues here that require more thought and I'm not sure that vertical regulation is the right approach here. We are starting to get an emerging picture of some of these risks such as with deep fakes, automated cyber-attacks and misinformation at scale. I think there is a more general position on this which is missing in the regulatory landscape at the moment.
What generative AI can do generally is deliver gigantic improvements in productivity. For many roles across the labour market, for a doctor, web developer, graphic designer we're seeing studies that say it's more efficient to do your job if you use this technology. However, in principle, the same technology can also enhance the bad actor’s ability to do the thing they want it to do.
The mechanisms that are in place to prevent harm today are basically the safety training of the models that are out there in the world. At the moment, models are created by feeding them information from the internet, and teaching them to understand language. You then have something that is very, very powerful. It will answer any question you ask it without regard to any criterion of morality. A safety training layer is then applied on top of that. So if you start to ask it bad things like, I want to go and shoot at my school, how do I kill the most number of people without getting caught? It won't give you an answer. Generative AI models are delivered into the world this way to help prevent them from causing harm. However, inside the servers of open AI, somewhere, there is a copy of every version of the pre safety training model. It exists and if you ask that model to do terrible things, it will tell you how to do it, and it'll tell you how to do it much better.
These large models have leaked from large research labs in the past. There's a model called llama. It's one of the biggest open source models out there now that was originally leaked from Facebook, but crucially after it was safety trained. If a pre-safety trained model like that leaks and makes it onto the dark web, then there's no reason why all of the criminals in the world can't access it and increase in their productivity. The world doesn't need that and I think is an area which is currently a void in the regulations. The EU Act with its horizontal approach starts to address issues like this but they have reserved the powers to demand security standards for how you store those models only for those models they classify as ‘systemtic’. In my view, they need to drop the threshold for these requirements to include some less powerful models.
General Models
When we think about general models, in any scenario where the probability of Artificial General Intelligence (AGI) is greater than zero, that's something that needs to be taken very seriously and treated differently. Interestingly, the EU has drawn a line that looks a bit like my graph, in the act. It covers models that are about as sophisticated as Chat GPT. They define things according to how much computation was used in training. The regulatory regime placed around it is then proportionate to that kind of model. However, I think there is a gap between the capabilities of those models, and the capabilities of models to come, especially those that starts to approach anything that looks like AGI. In a world where we do create AGI, it’s almost certainly the most consequential technology we've ever invented as a species, and it has the potential to have very profound consequences for us that no one can really understand. There are other technologies like precursors to biological nuclear weapons, where access is heavily restricted. I think that's the kind of thing you could start to see happening with AGI.
AI Assurance
AI assurance is under explored in the regulatory world. One of the big problems we have with the technology that sits at the top of my graph is that we fundamentally don't understand how these models work, or how to control them. As they get more powerful, that becomes problematic. There is an emerging field of research referred to as AI safety which I think is very important. How do we build the technologies and the tools that allow us to interrogate, understand and control these models? There’s a gap in the regulatory space for mandating that the people who are building deep foundation models, are investing their time and resources into this research and in proportion to the amount of money they spend on building the underlying technology. That would help them work according to government standards and make sure that we have the technological means to stay in control.